Why LLM Costs Balloon: Understanding the True Cost Drivers of AI
Large Language Models (LLMs) are often perceived as inexpensive due to low per-token pricing. However, as usage scales, many organizations experience rapid and unexpected cost growth. This is not caused by a single factor, but by the combined effect of token-based pricing, infrastructure requirements, and non-linear scaling behavior.
This article explains the primary cost drivers behind LLM-based systems and why costs tend to increase faster than expected.
1. Token-Based Pricing Models
Most commercial LLM providers charge based on token usage rather than per request. Tokens represent chunks of text and include both the content sent to the model and the content generated by it.
Costs are incurred for:
- Input tokens: system prompts, instructions, conversation history, retrieved documents, metadata
- Reasoning tokens: intermediate tokens generated during the model’s internal reasoning and planning steps, even when not fully exposed in the final response
- Output tokens: generated responses, reasoning steps, formatting, and structured outputs
In practice, input tokens often account for the majority of total usage, particularly in applications that rely on conversational context or retrieval-augmented generation (RAG). Every request repeats much of this input, which results in significant cumulative cost at scale.
2. Output Length and Response Complexity
Output tokens are more visible and therefore often easier to reason about, but they still represent a meaningful cost driver.
Common contributors to increased output length include:
- Detailed or explanatory responses
- Multi-step reasoning
- Structured or formatted outputs (JSON, tables, markdown)
- Safety and compliance-related verbosity
While the marginal increase per request may appear small, high request volumes can turn minor output inflation into substantial monthly expenses.
3. Infrastructure and Operational Costs
Token pricing reflects only the cost of model inference. In production environments, additional costs frequently emerge and may equal or exceed model usage costs.
Typical infrastructure and operational cost drivers include:
- GPU or accelerator compute (for self-hosted or fine-tuned models)
- Vector databases for embeddings and retrieval
- Storage and data transfer between services
- Monitoring, logging, and evaluation pipelines
- Retry logic and fallback requests due to timeouts or low-confidence outputs
- Engineering effort required to maintain and optimize the system
As systems mature, these costs become increasingly material and must be considered as part of the total cost of ownership.
4. Non-Linear Scaling Effects
LLM system costs rarely scale linearly with user growth. As usage increases, systems tend to evolve in ways that increase per-request cost.
Examples include:
- Larger prompts due to longer conversation histories
- Additional retrieved context to improve answer quality
- Multiple model calls per user interaction (routing, validation, retries)
- Higher latency requirements leading to more powerful (and expensive) models
As a result, both request volume and cost per request tend to increase simultaneously.
To put some context around - a concrete example of this is illustrated in a Latenode forum discussion:
- Legal Document Analysis Disaster: A user working with legal documents reported that each follow-up question about specific clauses resulted in re-sending the entire 40-page contract every time, causing the token meter to "spin like a slot machine."
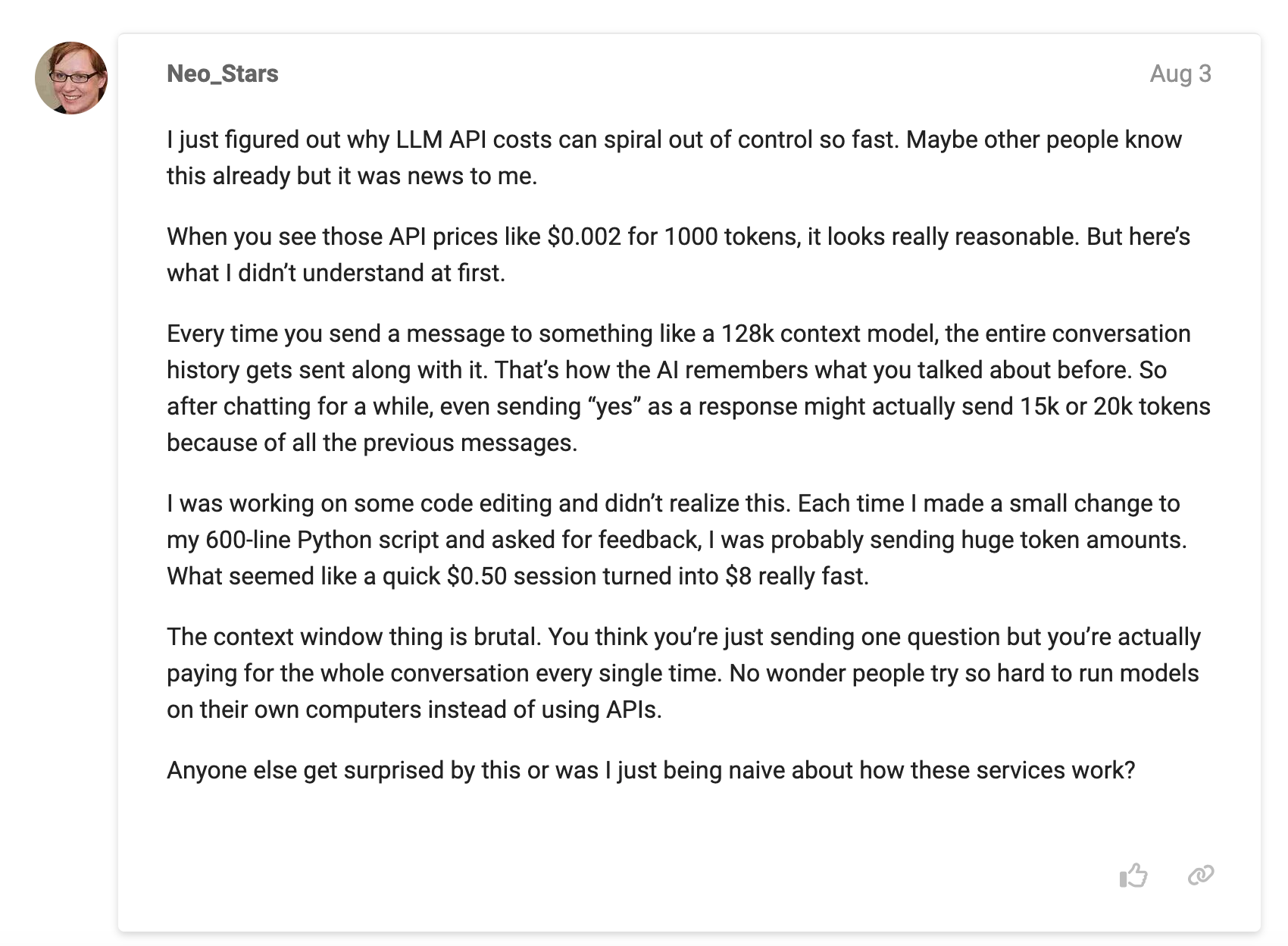
- Coding Context Accumulation: Another user reported a coding session where what seemed like a quick $0.50 session turned into $8 really fast due to context accumulation, which continually re-sent the entire code script with every request.

Additionally, we can highlight another example of this rapid, non-linear cost growth was reported by a user running a website chatbot. Since November 17, 2023, the user experienced a sudden 6-10x cost explosion, with the usage shown on the API dashboard being significantly higher than the actual token usage by visitors. (OpenAI Developer Community Discussion)
5. Common Reasons Costs Are Underestimated
Early-stage prototypes and proofs of concept often mask future cost behavior. Common reasons for underestimation include:
- Small-scale testing that does not reflect real-world usage patterns
- Limited visibility into token consumption across the system
- Ignoring infrastructure and operational costs during planning
- Assuming early optimization can be deferred without financial impact
Without deliberate cost controls, LLM usage can quickly become one of the fastest-growing expenses in an AI-enabled product.
6. Industry Context
The scale of LLM costs becomes clear when looking at industry data. OpenAI is expected to spend nearly $4B this year on ChatGPT inference alone, running on about 350,000 Nvidia A100 servers at close to full load. This shows that the same cost pressures users face, especially infrastructure, also affect the biggest companies. (Data Center Dynamics Report)
The trend is broad. The CloudZero 2025 AI Spending Report shows average monthly enterprise AI spend rising from $62,964 in 2024 to $85,521 in 2025 (36 percent growth). The share of companies spending more than $100K per month is projected to increase from 20 percent to 45 percent. (CloudZero 2025 AI Spending Report)
A direct industry citation captures the reality of consumption at scale. Pavel Nesterov, Executive Director of DS and AI at Revolut, wrote:
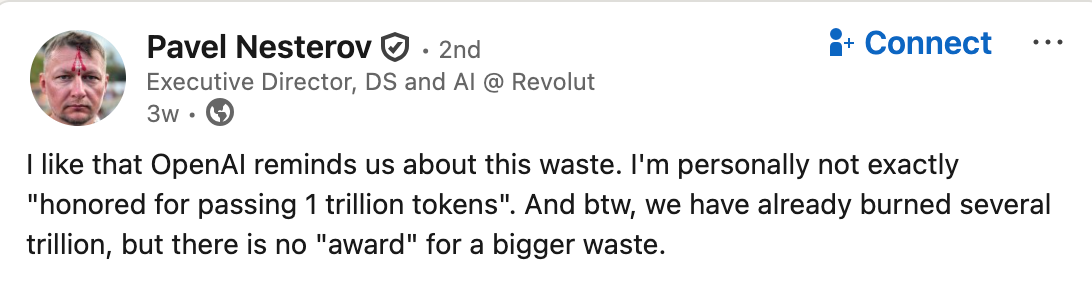
“I like that OpenAI reminds us about this waste. I'm personally not exactly honored for passing 1 trillion tokens. And btw, we have already burned several trillion, but there is no award for a bigger waste.” (LinkedIn Post)
Conclusion
LLM costs increase due to a combination of token-based pricing, hidden infrastructure expenses, and non-linear scaling dynamics. Understanding these drivers is essential for building sustainable, production-ready AI systems.
In the next article in this series, we will focus on practical prompt and token optimization techniques that can reduce costs immediately, without architectural changes.
If you want to know more about reducing your inference costs, please contact us.
