Why most AI use cases fail - and how to make them economically viable. Part 3: AI Adoption Red Flags
Your AI pilot worked. Leadership was impressed. In Part 1, we examined why most AI pilots fail economically - the trap of negative unit economics, the hidden complexity of proprietary data, and whydemos rarely reflect production reality. In Part 2, we tackled the scaling problem: how optimization strategies can cut costs by 30-80%, and why the gap between prototype and production catches most teams off guard.
But technical feasibility and cost optimization aren't enough. Most organizations still struggle with a more fundamental question: Should we build this at all?
1. Evaluating AI use cases through an economic lens
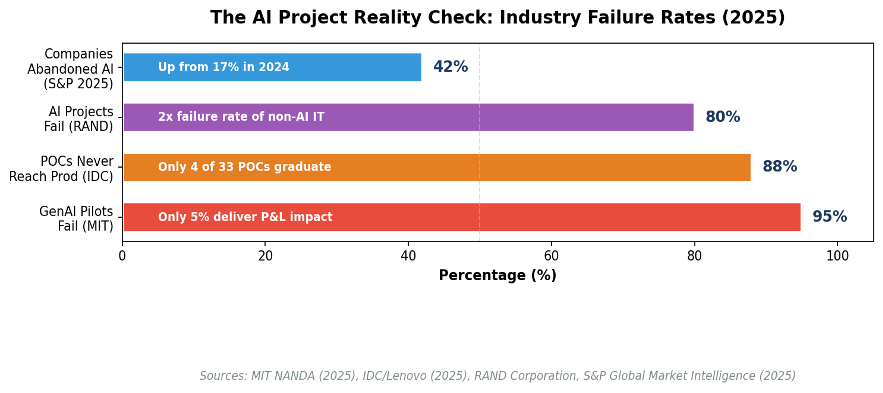
Before discussing evaluation criteria, consider the industry reality. According to MIT NANDA's 2025 study (The GenAI Divide:State of AI in Business 2025), 95% of generative AI pilots fail to deliver measurable P&L impact. IDC / Lenovo research (2025) found that only 4 of every 33 AI proof-of-concepts reach production. S&P Global reports that 42% of companies abandoned most of their AI initiatives in 2025 - up from just 17% in 2024:
Before scaling an AI use case, teams should be able to answer the following questions with confidence:
- What is the cost per unit of business value delivered?
- How does cost scale with usage, data volume, and system complexity?
- How much proprietary data is required per interaction?
- Which components drive most of the total cost?
- What optimization options exist without hurting outcomes?
- At what scale does the use case break even?
Teams can use this scorecard to systematically evaluate each dimension before committing resources:

These questions shift the discussion from “Can we build this?” to “Should we run this in production?”
Prioritization Framework: Impact vs. Feasibility
According to research from Microsoft's BXT framework and the ICE scoring methodology, AI use cases should be evaluated across two primary dimensions: business impact and implementation feasibility. According to Kowalah up to 87%of AI projects never reach production - focusing on technology rather than genuine business problems is the most common cause:
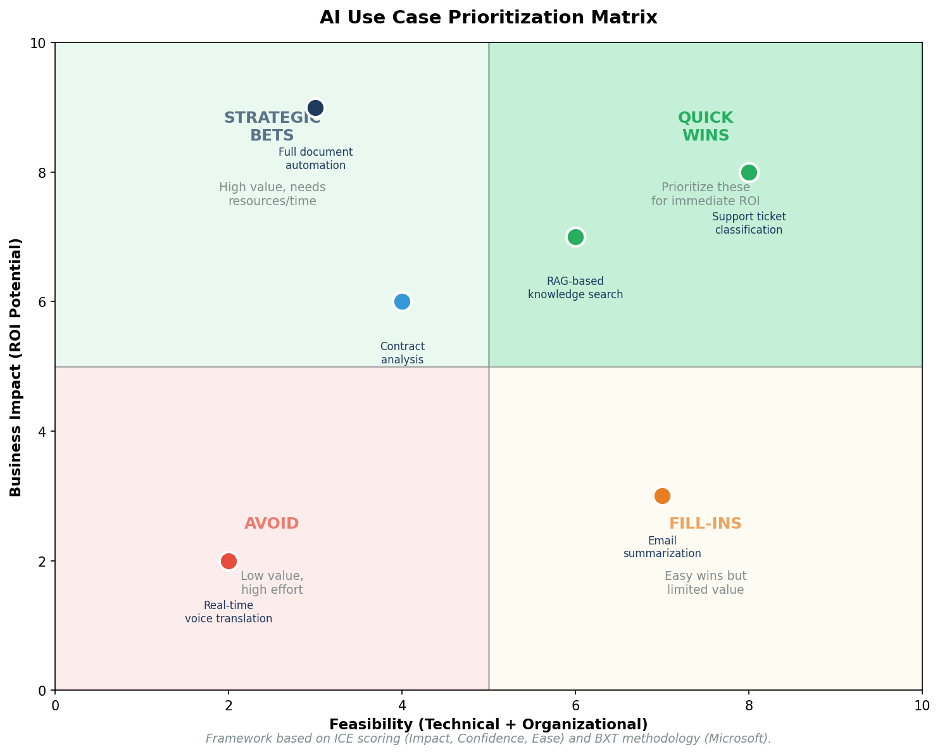
ICE Scoring for AI Use Cases
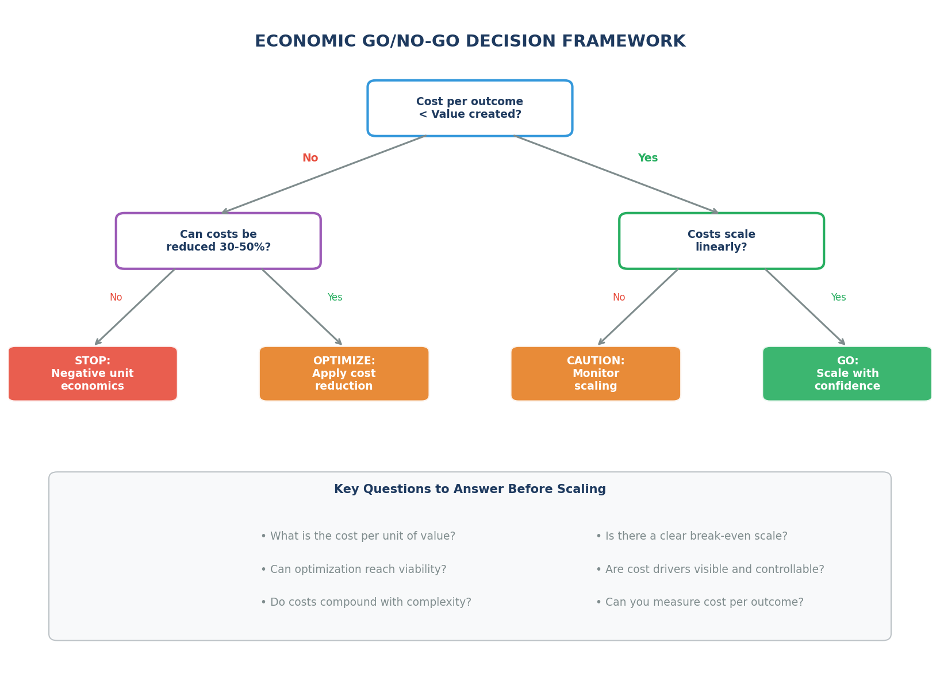
Economic Go/No-Go Framework
Not every AI idea deserves investment. The following decision framework helps teams make go / no-go decisions based on economic fundamentals:
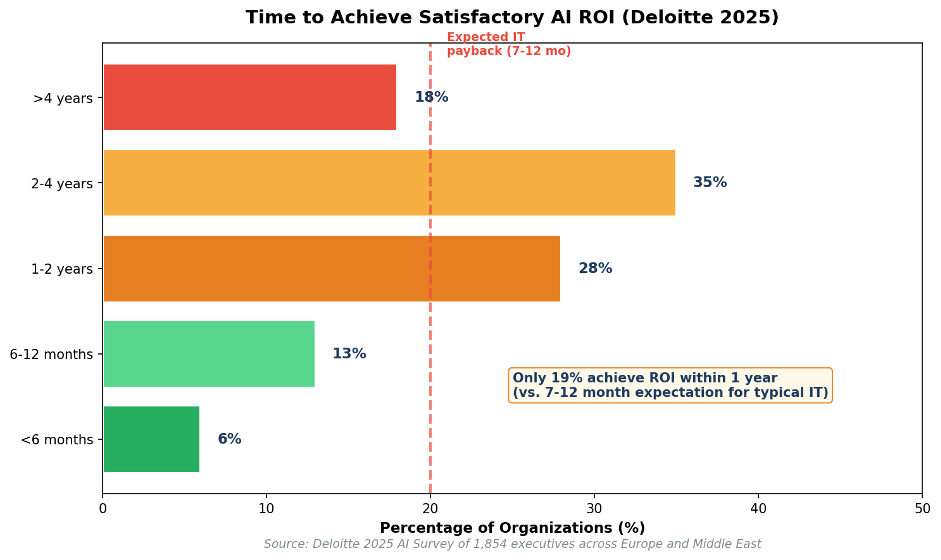
ROI Timeline Reality
According to Deloitte's 2025 AI survey of 1,854 executives across Europe and the Middle East, AI ROI takes significantly longer than typical IT investments. While traditional technology projects expect payback in 7-12 months, most AI projects require 2-4 years to achieve satisfactory ROI:
Available Evaluation Frameworks
Key Economic Metrics to Track
Key Insight
According to MIT's research, the core barrier to AI success is learning - not infrastructure, regulation, or talent. Most GenAI systems do not retain feedback, adapt to context, or improve over time. Teams that focus on workflow integration and domain specificity achieve 2x higher success rates than those pursuing general-purpose solutions.
Key statistics
- 95% of GenAI pilots fail to deliver P&L impact
- 88% of AI POCs never reach production
- Only 19% of organizations achieve AI ROI within 1 year
- 87% of AI projects never reach production due to focus on technology over business problems
- Vendor-purchased AI succeeds 67%of the time vs. 33% for internal builds
A concrete example
Talking about AI costs in general is useful, but decisions are made on numbers. So let’s look at one real case.
Imagine a support team handling about 50,000 tickets per month. The goal isn’t full automation. The system just helps: it classifies tickets and drafts replies so humans spend less time on each one. Each ticket is worth roughly €1.50 in saved cost or protected revenue.
What the prototype looks like
At the pilot stage, the setup is typical.
One large model handles everything.The full conversation history is sent every time. The system pulls in a wide set of internal documents “just to be safe”. The model explains its reasoning in detail. Nothing is cached.
On average, each request uses about:
- 4,500 input tokens
- 1,500 reasoning tokens
- 1,000 output tokens
That’s 7,000 tokens per ticket.
At an effective blended cost of €0.003 per 1,000 tokens, each ticket costs about €0.02. Across 50,000 tickets, that’s roughly €1,050 per month.
On paper, this looks fine.
But this number leaves out most production costs: vector databases, retrieval infrastructure, monitoring, retries, peak traffic, and the engineering work needed to keep the system running. Once those are included, the real cost per ticket rises to around €0.07–€0.09, pushing monthly cost to €3,500–€4,500.
At that point, margins shrink fast. For lower-value tickets, the economics start to fall apart entirely.
After basic optimization
Now look at the same system after straightforward cost work.
The prompt is shorter. Only the most relevant documents are retrieved. Reasoning is limited where the task is deterministic. Smaller models handle most tickets. Repeated or near-duplicate requests are cached.
Token usage drops to about:
- 1,800 input tokens
- 400 reasoning tokens
- 400 output tokens
That’s 2,600 tokens per ticket, or about €0.008.
At 50,000 tickets, inference cost falls to roughly €390 per month. Add infrastructure and operations, and total monthly cost lands around €700.
Nothing about the use case changed. No new models. No breakthroughs. Just discipline around cost.
That’s the difference between a system that looks good in a demo and one that actually survives in production.
When an AI use case should not be built
Sad, but true. Not every AI idea deserves to reach production. In some cases, the right decision is to stop early - before more time and money are sunk into something that will never work economically.
Here are clear signals that an LLM-powered use case should be dropped, delayed, or fundamentally rethought.
Flag 1. When the numbers can never work 🚩
If the cheapest possible version of the system still costs more than the value it creates, the use case is dead on arrival.
Typical examples:
- Spending €0.20 in AI cost to automate a €0.10 task
- AI triage that costs more than offshore human review
- AI “insights” that don’t change decisions or outcomes
No amount of tuning fixes negative unit economics. If the math doesn’t work at the bottom, it won’t work at scale.
Flag 2. When proprietary data dominates the cost 🚩
Some use cases are expensive not because of the model, but because of the data they depend on.
This often shows up when the system needs:
- Large proprietary documents on every request
- Frequent full-context injection
- Heavy compliance, audit, or access-control requirements
If the use case cannot tolerate:
- Aggressive context reduction
- Partial or selective retrieval
- Approximation, summarization, or caching
then costs tend to stay high forever. In these cases, the system rarely stabilizes economically.
Flag 3. When determinism matters more than intelligence 🚩
LLMs are probabilistic by nature. If a use case requires:
- Fully deterministic outputs
- Strict repeatability
- Zero tolerance for deviation
then LLMs are often the wrong tool.
Rules engines, traditional software, or search systems are usually cheaper, safer, and easier to operate. Using an LLM here adds cost and risk without adding real value.
Flag 4. When latency and cost fight each other 🚩
Some use cases demand all three at once:
- Very low latency
- High throughput
- Tight cost limits
If meeting latency targets requires:
- Large models
- High parallelism
- Over provisioned infrastructure
then the economics often break as soon as traffic grows. These systems look fine at low volume and collapse under real load.
Flag 5. When AI only adds a small improvement 🚩
AI is easy to overuse.
If it:
- Slightly improves an already acceptable workflow
- Produces “nice to have” insights
- Replaces something that was never a real bottleneck
then ROI is usually overstated.
AI is most defensible when it does one of three things: replaces a meaningful cost center, enables revenue that wasn’t possible before, or unlocks scale humans can’t provide.
Flag 6. When you can’t see the economics 🚩
If you can’t reliably measure:
- Cost per request
- Cost per outcome
- Token usage by component
- Failure and retry rates
then you can’t control costs.
Systems you can’t observe are almost guaranteed to blow past budget over time.
Closing thought
Knowing when to say “no” is as important as knowing how to build.
LLMs are powerful, but they are not universally economical. Clear kill criteria protect teams from spending months optimizing systems that will never make sense in production.
The strongest AI teams aren’t the ones that build the most use cases. They’re the ones that are disciplined about which ones they choose to run.
In Part 4, we'll explore how to design AI systems that are economically sustainable in production - covering cost observability, quality-cost-latency tradeoffs, and the design checklist that separates systems that survive from those that collapse under their own economics. Stay tuned.
