Why most AI use cases fail - and how to make them economically viable. Part 1: Why AI Fails?
95% of generative AI pilots fail to deliver measurable P&L impact. That’s not a pessimistic estimate - it’s the finding from MIT NANDA’s 2025 study on enterprise AI adoption. IDC/Lenovo research found that only 4 of every 33 AI proof-of-concepts ever reach production. And S&P Global reports that 42% of companies abandoned most of their AI initiatives in 2025 - up from just 17% in 2024. The reason is simple: most AI use cases cost more than they return.
Large language models can automate support, assist sales teams, analyze documents, and speed up internal decisions. But once pilots move toward real usage, costs grow faster than expected. Without clear control over unit economics, promising experiments stall before reaching production.
If you ever asked yourself “Gosh, the demo was cheaper”, you are not alone. This article shows how AI costs are formed, why they often spiral, and what determines whether a use case can scale sustainably instead of dying after the pilot phase.
1. Why many AI use cases don’t make economic sense
Most AI pilots don’t fail because the technology is bad. They fail because the numbers never worked. According to VentureBeat, up to 87% of AI projects never reach production - and the most common cause is focusing on technology rather than genuine business problems.
From a demo point of view, everything looks fine. The model answers questions, classifies data, and produces useful output. But once teams look at real usage, costs quickly start to dominate.
The warning signs are usually obvious:
● The cost per interaction is high compared to the value it creates
● AI improves an existing workflow, but only slightly
● Monthly spend is hard to predict and keeps climbing
● Unit economics break as soon as volume increases
In many organizations, feasibility is judged by model quality alone: accuracy, reasoning ability, benchmark scores.Cost is treated as something to “optimize later”.
That approach breaks down fast, especially when proprietary data is involved. Retrieval pipelines, preprocessing, access control, governance, and compliance all add real cost.These costs are easy to ignore in early experiments — and impossible to ignore in production.
As a result, many AI use cases don’t fail technically. They fail economically. Research from McKinsey suggests that only about 1% of companies consider their AI deployments mature - meaning AI is fully integrated and delivering consistent value.
2. Unit economics as the foundation of viability
Every AI use case comes down to a simple question: how much does one useful outcome cost?
Not one model call. Not one prompt.One outcome that matters to the business.
Depending on the use case, that outcome might be:
● A resolved support ticket
● A qualified sales lead
● A document reviewed or summarized
● A decision supported with reliable input
If the cost of producing one outcome is close to - or higher than - the value it creates, the system cannot scale.It may look impressive in a demo, but it will collapse under real usage.
This is why unit economics matter more than aggregate spend. Total monthly cost hides the problem. Cost per outcome exposes it.
Until teams can answer "What does one result cost us?", discussions about scaling, optimization, or ROI are premature.
The fundamental equation for AI unit economics:

LLM-based systems introduce costs that change with usage. These costs are not fixed, and they don’t grow linearly.
Several factors drive them:
● Input, reasoning, and output tokens
● How many model calls each workflow makes
● Infrastructure and orchestration overhead
● Errors, retries, and fallback logic
● Data access patterns, especially when proprietary data isinvolved
To control costs, teams first need to understand where they actually come from. The breakdown below shows a typical cost composition for 1,000 LLM requests.
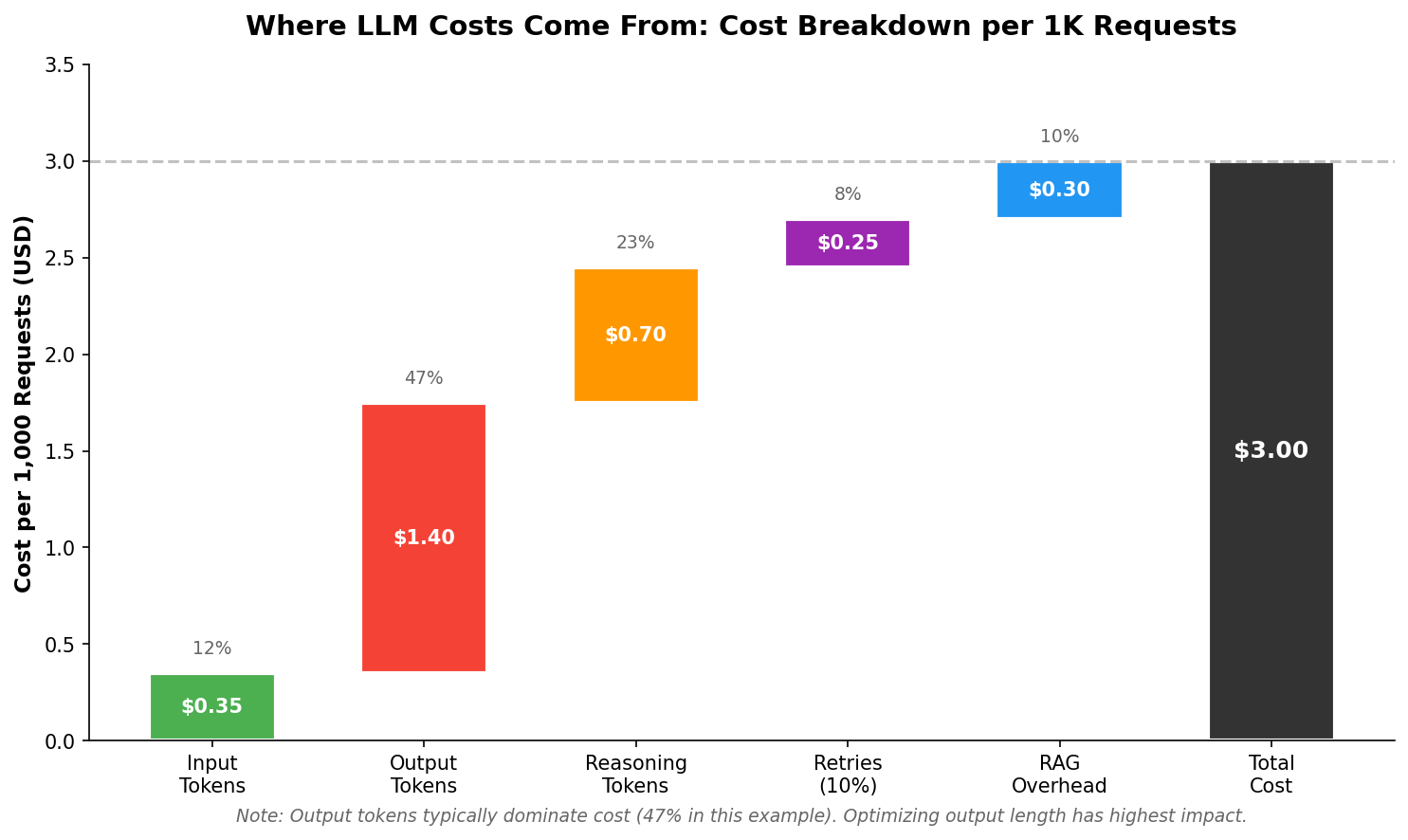
In most LLM workflows, output tokens account for the largest share of cost (47% in this example). That’s why the biggest savings usually come from two simple actions: keeping outputs shorter and limiting how much reasoning the model produces.
Tools like Helicone and Langfuse help teams see these costs in real time, breaking spending down by input tokens, output tokens, retries, and latency.
For context, current flagship models typically charge $1.50–5 per million input tokens and $12–25 per million output tokens. Output is usually 3–8× more expensive than input. Caching repeated context can cut costs dramatically, with discounts of up to 90%. For up-to-date pricing across 300+ models, see LLM Price Check or Vellum’s comparison tool.
Model pricing is also changing fast. According to research from EpochAI, inference prices for frontier-level performance have dropped by up to 900× per year. A use case that looks too expensive today may become viable much sooner than expected.
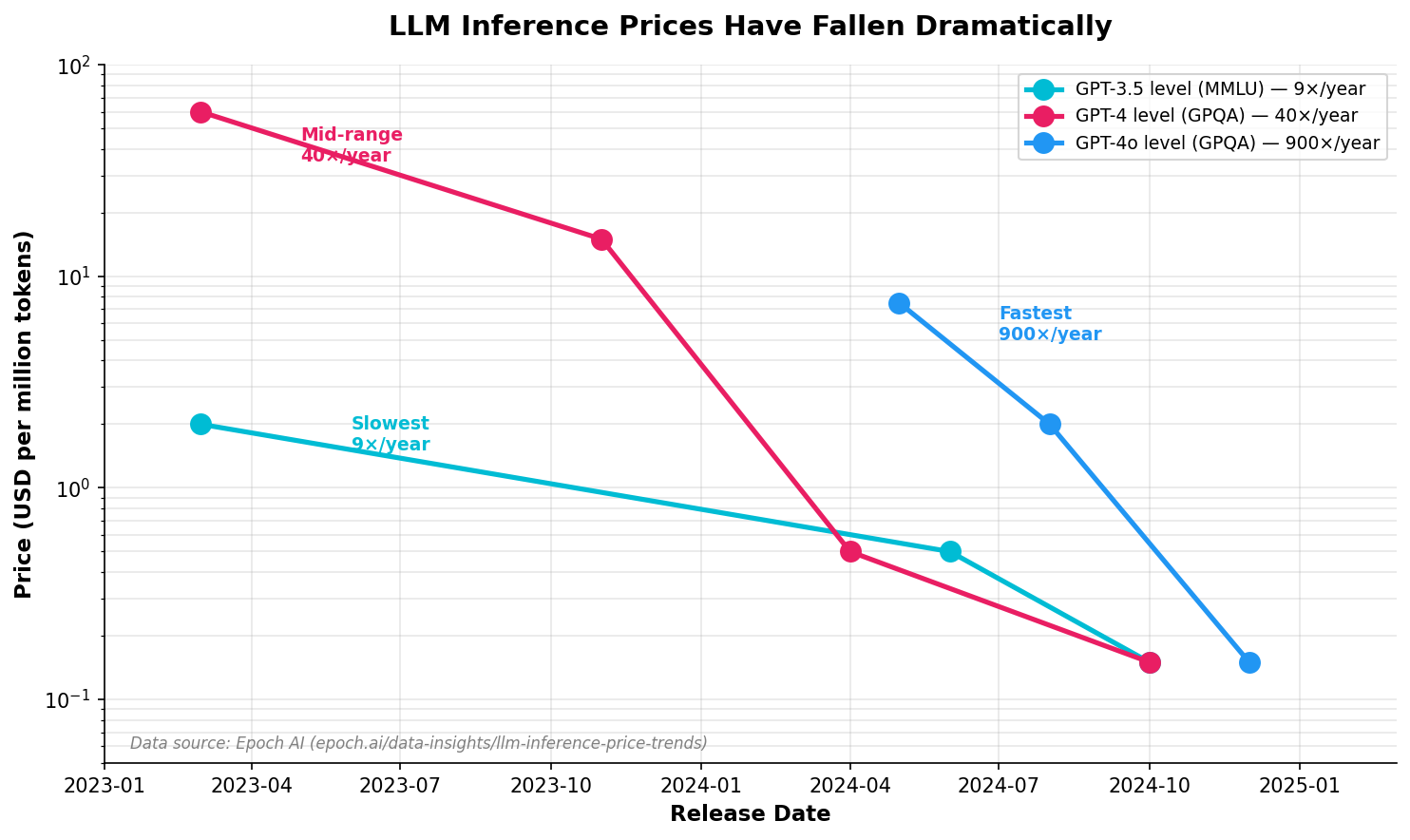
What this means in practice: A use case that is slightly unviable today may become economically feasible within months. Pricing moves fast, so unit economics should be revisited regularly.
Current API pricing (January 2026)
The following tables show typical pricing at the time of writing. Always check the official pages for the latest rates: OpenAI, Anthropic, Google.
OpenAI Models
Note: GPT-5.2 offers 90% cache discount ($0.175/1M). Variants: Instant (fast), Thinking (reasoning), Pro (max intelligence). Reasoning tokens billed as output.
Anthropic Claude Models
Google Gemini Models
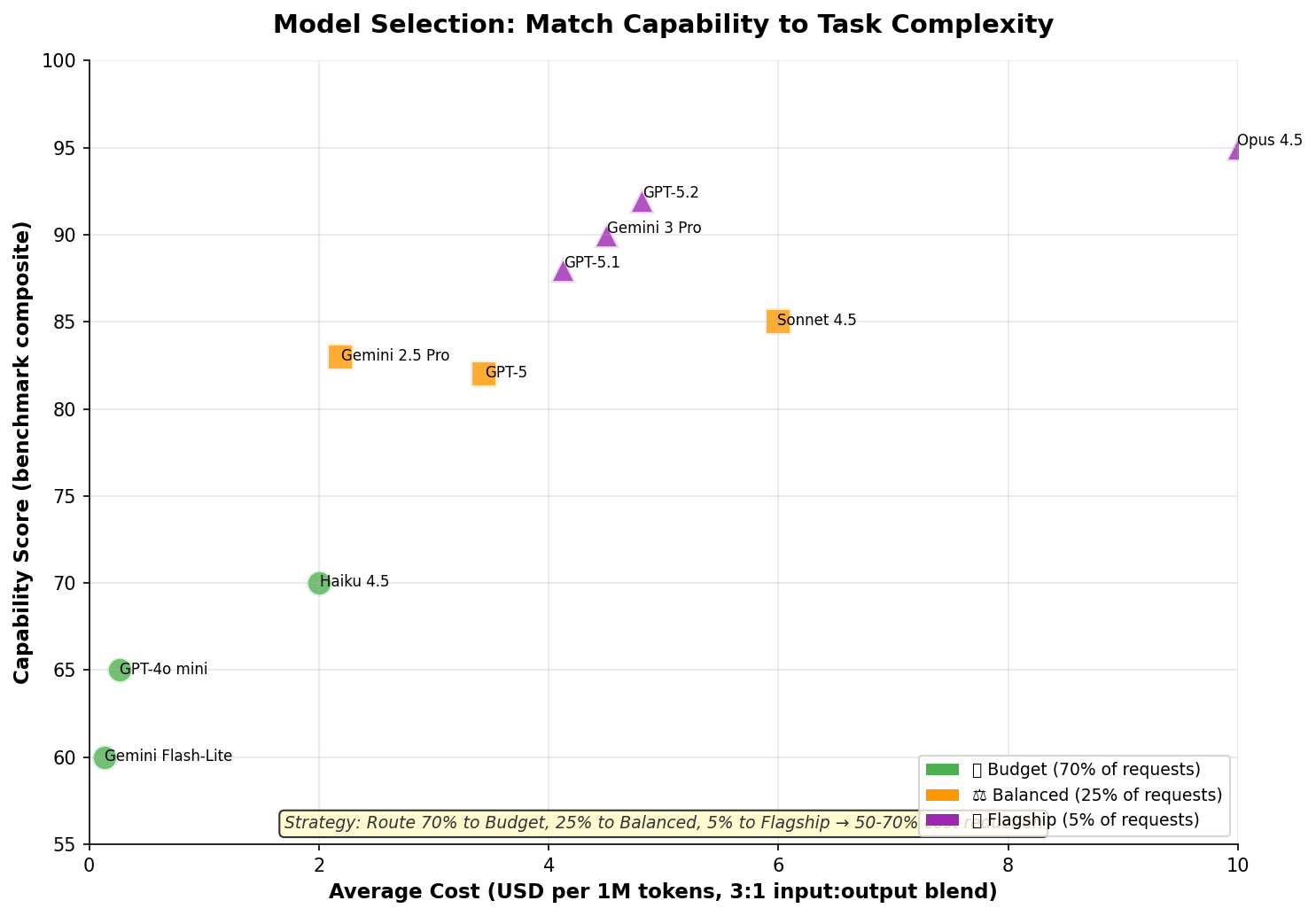
Model selection strategy
Not every request needs a flagship model. Matching model capability to task complexity can cut costs by 50–70%.
Research from AIMultiple shows that routing around 70% of requests to lower-cost models, while reserving flagship models for harder tasks, delivers the best return on investment.
Without clear visibility into these cost drivers, unit economics stay unstable and hard to defend.
Modern LLM observability tools make this visibility practical with minimal setup. Helicone can be added as a proxy with a single integration and provides cost tracking, caching, and alerts (free tier: 10K requests per month). Langfuse is open source, can be self-hosted, and supports prompt versioning. LangSmith integrates closely with LangChain for tracing and evaluation (free tier: 5K traces per month).
These tools help teams see where money is actually spent, catch cost regressions early, and defend unit economics before scaling.
3. Datatype as a cost multiplier
The type of data an AI system works with has a direct (and often decisive) impact on cost.
Research from enterprise RAG deployments shows that data type alone can increase per-request costs by 5–20×. According to analysis from Zilliz, use cases involving proprietary data require multiple additional infrastructure layers:
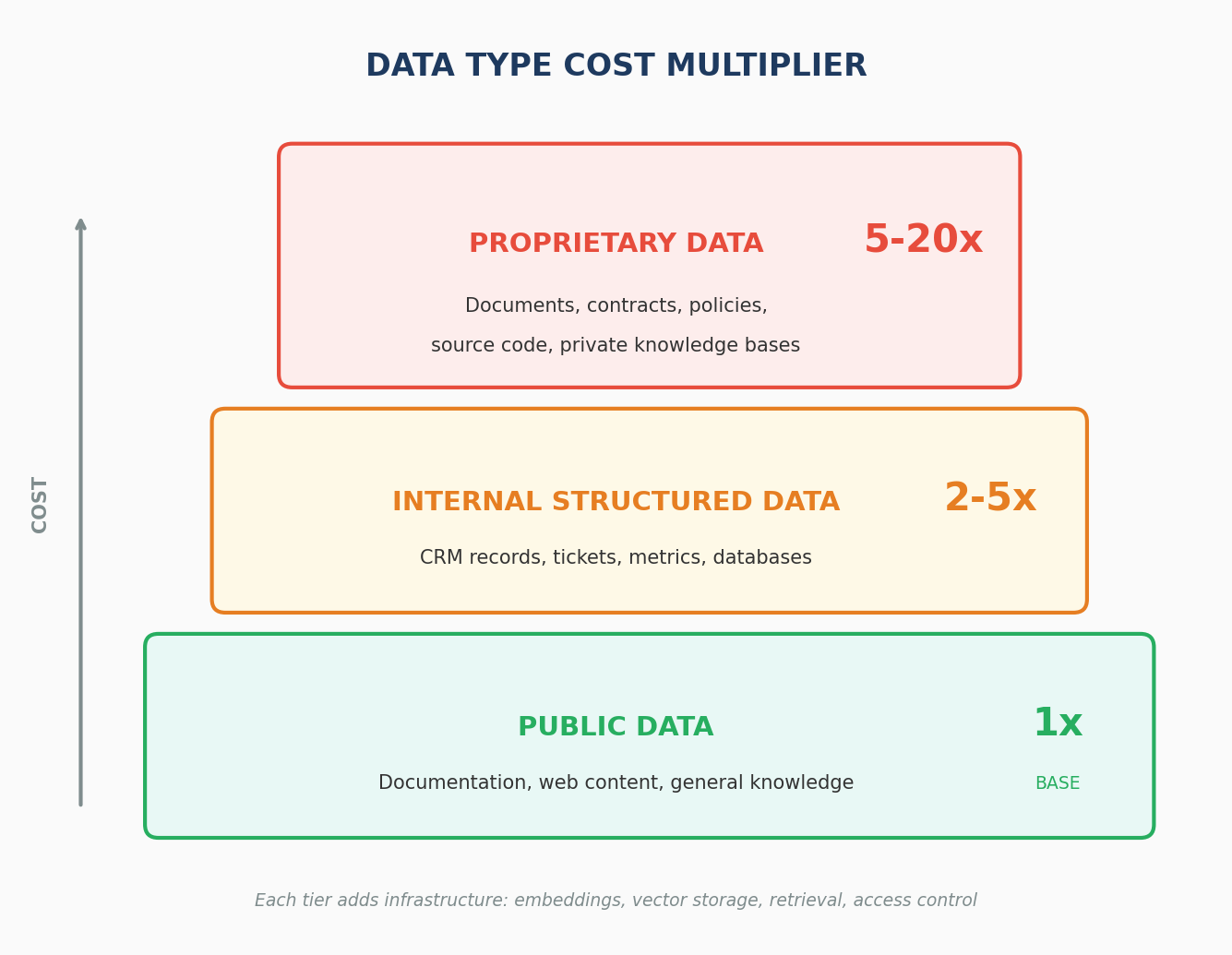
Common data categories include:
● Public data (documentation, web content, general knowledge)
● Internal structured data (CRM records, tickets, metrics)
● Proprietary data (internal documents, contracts, policies, source code, private knowledge bases)
Use cases that rely on proprietary data usually require:
● Embedding and indexing pipelines
● Vector databases and retrieval layers
● Context assembly and ranking logic
● Access control, auditability, and compliance mechanisms
Each additional layer increases the cost of every request. The diagram below shows how these costs accumulate.

Each additional layer increases the cost of every request. Without careful system design, use cases that rely heavily on proprietary data can become economically unsustainable, even when the business value is clear.
Understanding RAG system costs
A RAG system has five main cost components. According to analysis from TheDataGuy, these components interact and compound rather than behaving independently:
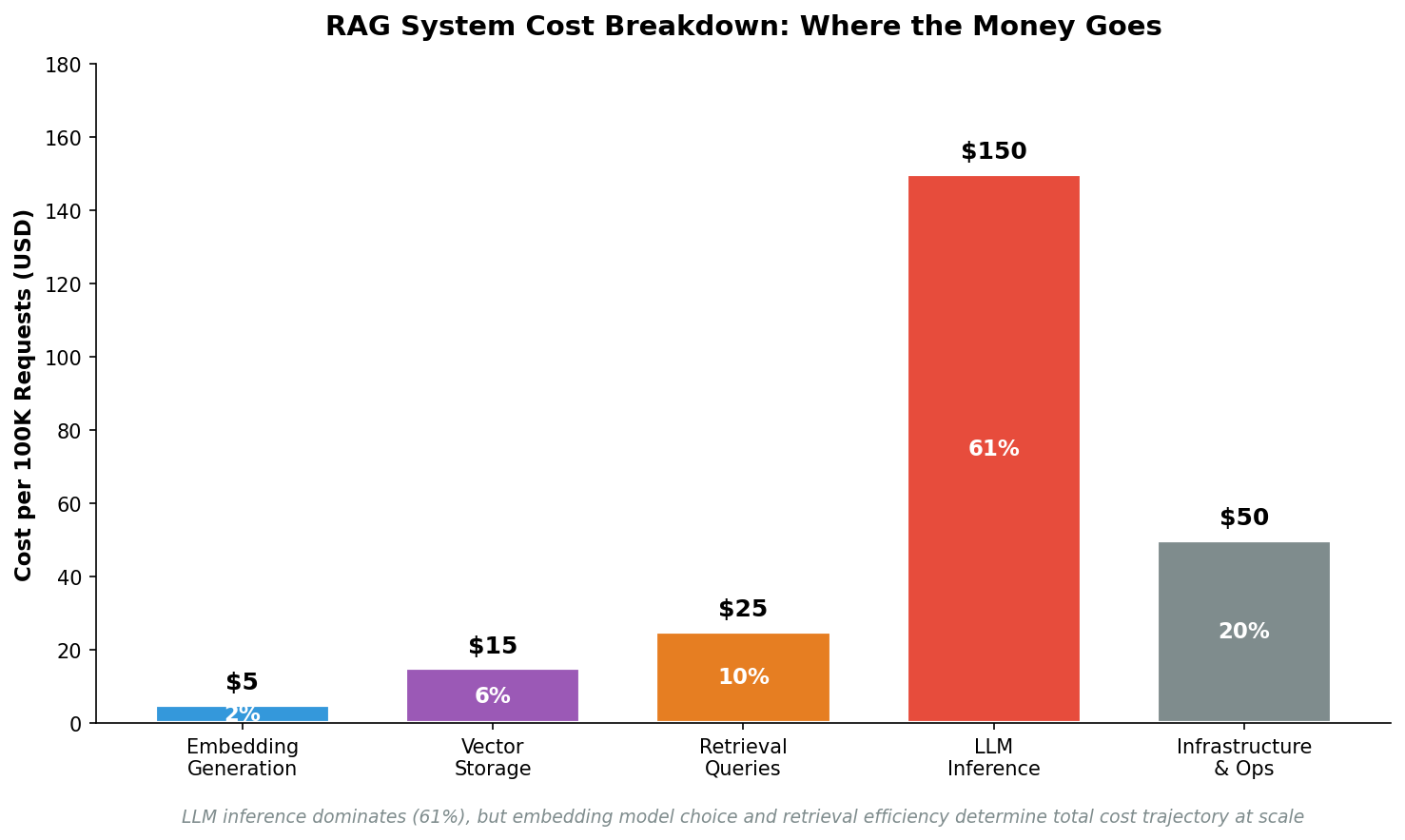
While LLM inference accounts for the largest share of cost (61%), embedding model choice shapes long-term economics. In enterprise RAG systems, poor embedding decisions can push total costs up to 300% higher than necessary.
Embedding model economics
Embedding models convert text into numerical vectors that represent meaning in a form machines can compare and search efficiently. Pricing has largely commoditized. As a reference point, embedding the entire EnglishWikipedia now costs around $650.
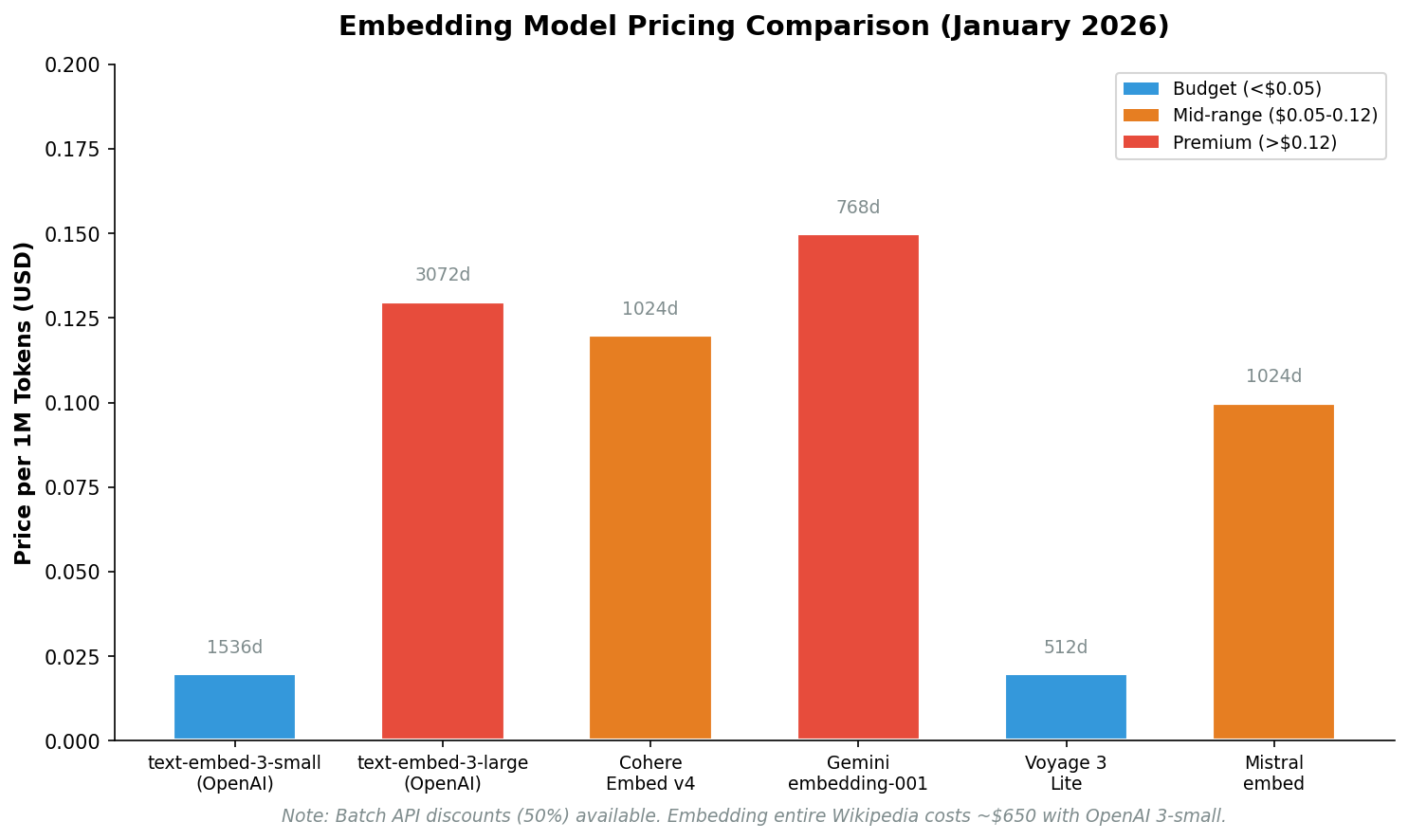
Embedding Model Pricing Table
Vector Database Economics
Vector databases store embeddings and enable similarity search. Choice depends on scale:

Conclusion
The economics of AI determine whether a use case lives or dies. Unit economics - the cost per useful outcome - is the foundation of viability. Data type acts as a cost multiplier, with proprietary data adding layers of infrastructure that can increase per-request costs by 5–20×. Without visibility into these cost drivers, promising pilots stall before reaching production.
Next: Part 2 – Scaling Costs. We’ll cover how cost reduction strategies can transform unviable use cases into defensible ones, and why the gap between prototype and production economics catches most teams off guard.
