Why most AI use cases fail - and how to make them economically viable. Part 2: Scaling Costs
Your AI pilot worked. The demo impressed leadership. Now comes the hard part: scaling it without watching costs spiral out of control. Most teams discover too late that the economics of a prototype bear little resemblance to production reality. And by the time they do, architectural decisions have already locked in unsustainable cost structures.
This is Part 2 of a series on AI economics. In Part 1, we covered why most AI pilots fail economically - unit economics, data costs, and the hidden complexity of proprietary data. If you haven’t read it yet, start here.
In Part 2, we take on the scaling problem: how cost reduction strategies can transform unviable use cases into defensible ones, and why the gap between prototype and production catches most teams off guard. We’ll cover optimization techniques that cut costs by 30–80%,the hidden costs that appear only at scale, and the production readiness checkpoints that separate pilots that survive from those that don’t.
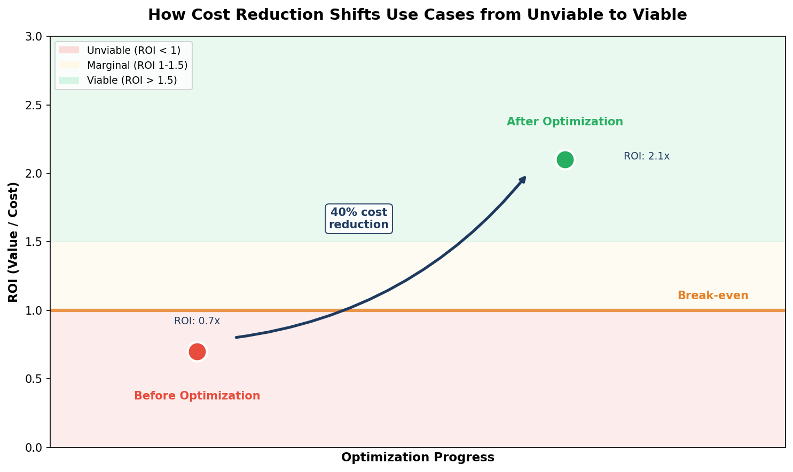
1. How cost reduction alters feasibility
Many AI use cases sit close to the line between viable and unviable. In these situations, even modest efficiency gains can change the outcome. According to research from Koombea, strategic optimization can reduce LLM costs by up to 80% without sacrificing performance quality. The key insight: most production systems can achieve 60-80% cost reduction through systematic optimization. This transforms use cases that are marginally unviable into economically defensible production systems.
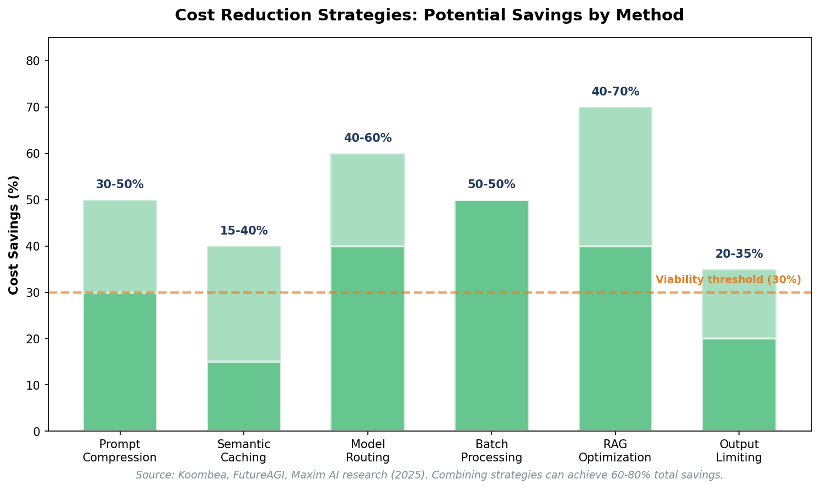
High-impact cost reduction strategies include:
- Reducing prompt size and removing redundant proprietary context
- Limiting output length and reasoning depth to what is actually needed
- Retrieving only the most relevant proprietary data
- Routing simple or deterministic tasks to lower-cost models
- Avoiding repeated retrieval and inference through caching and reuse
Research from FutureAGI, Maxim AI, and Ptolemay quantifies the savingspotential for each strategy:
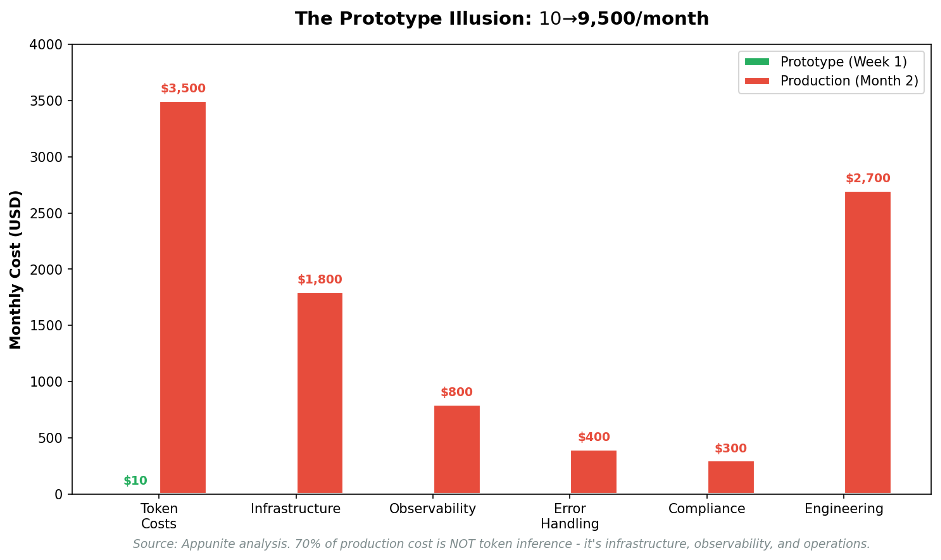
2. The gap between prototype and production economics
Early prototypes almost never reflect real production costs.
According to analysis by Appunite, the move from prototype to production can expose a 950× cost increase. A pilot that costs $10per month can grow to $9,500 per month within weeks as teams addRAG, observability, and error handling. Truly amazing.
Prototype systems typically have:
- Low request volume
- Limited use of proprietary data
- Short prompts and small context windows
- Manual oversight and corrections
Production systems are very different:
- Sustained high concurrency and throughput
- Large and constantly changing proprietary context
- Automated retries, validation, and fallback paths
- Strict latency, reliability, and compliance requirements
The table below quantifies these differences. Industry research shows that many AI teams significantly exceed their budgets during scaling:

This transition is where many AI initiatives fail financially. Costs tied to proprietary data access and system complexity often appear late and grow faster than teams expect.
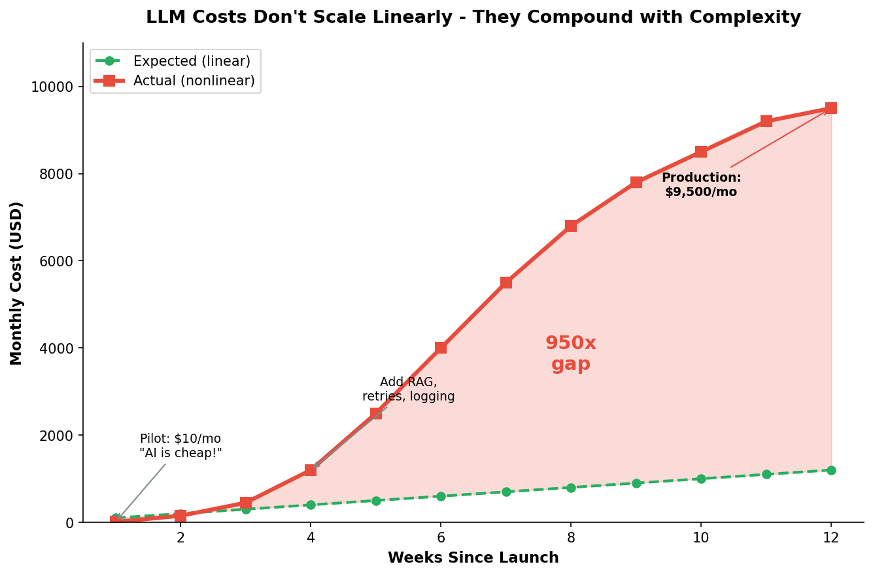
Why costs don’t scale linearly
LLM costs grow with system complexity, not just with usage. Accordingto NStarX, one CIO put it simply: “WhatI spent in 2023 I now spend in a week.” Enterprise leaders expect 75% growth in LLM spending over the next year.
Hidden production costs
According to MetaCTO, “bill shock” is the most common problem when teams move from prototype to production. Costs that were invisible early on start to add up quickly.

Production cost components
Key statistics
- Around 95% of GenAI pilots fail to deliver measurablebusiness impact and never make it into sustained production, according toresearch from MIT
- Only about 1% of companies consider their AI deployments mature, meaning AI is fully integrated and delivering consistent value, according to industry research cited by McKinsey and Gartner
- Roughly 70% of production AI costs come from infrastructure and operations, not token inference
Production readiness checklist
Before scaling, teams should put basic cost controls in place. According to Tribe AI, organizations that complete these checkpoints reduce production costs by 50–70%.

Cost control strategies
Comment: Here I felt that I've read the same in this article before. See page 3. Maybe we need to discuss Production infrastructure only once in our article along this other mitigation strategies.
Production infrastructure tools
Several tools help teams manage the transition from prototype to production. Langfuse and Helicone provide observability with per-request cost tracking.
Bifrost by Maxim AI offers an LLM gateway with low overhead (around 11 microseconds) and automatic failover. vLLM and TGI (Text Generation Inference) support high-throughput, self-hosted inference. For cost estimation, the Ptolemay LLM Cost Calculator helps teams forecast production budgets.
Key insight

Pilot costs are not a prediction - they are misleading. By the time teams start optimizing a production system, most cost drivers are already locked in by architectural choices made during prototyping. Systems that are meant to scale economically need to be designed with production costs in mind from day one. Briefly highlight the most interesting moments:
The 950× trap.
Teams routinely underestimate how costs multiply from prototype to production. A system that costs €10/month in testing can reach €9,500/month at scale—not because anything went wrong, but because pilot economics never reflected reality. The demo was always a lie.
Optimization has limits.
Cost reduction strategies can cut expenses by 30–80%, but they cannot fix fundamentally broken unit economics. If your cheapest possible version still costs more than the value it creates, no amount of prompt engineering or caching will save it.
Infrastructure costs are the quiet killer.
Token costs get all the attention, but vector databases, retrieval pipelines, monitoring, retries, and peak-load provisioning often double or triple the real cost per interaction. Teams that budget only for API calls discover this too late.
You can't optimize what you can't see.
Organizations without cost observability consistently find their AI bills 5× higher than budgeted. The teams that survive production are the ones tracking cost per outcome -not just cost per request.
The window closes fast.
Architectural decisions made during prototyping lock in cost structures that become expensive to change later. By the time economics become visible, the system is already built around assumptions that may never have been true.
What's Next
Knowing how to reduce costs isn't enough. You also need to know when a use case should never be built in the first place.
In Part 3, we shift from optimization to evaluation: how to assess AI use cases through an economic lens before committing resources, the frameworks that separate viable projects from money pits, and the kill criteria that protect teams from wasting months on systems that will never make sense in production.
